Large Language Model (LLM) Applications for Assessing Patient Health Communication Proficiency
Abstract Body (Do not enter title and authors here): Introduction: Health communication ability is a potent predictor of patient outcomes; assessing this ability is crucial for ensuring clinical consultations, health education, and literacy initiatives are effective. However, existing assessment methods lack scalability, consistency, and objectivity, presenting a need for a consistent, quantifiable metric for healthcare providers and clinical researchers to rigorously assess the health communication proficiency of patients.
Research Hypothesis: A Large Language Model (LLM)-driven Communication in Health Assessment Tool (CHAT) can be developed using a standardized rubric-based approach to quantify patient communication proficiency.
Methods/Approach: An LLM rubric-based assessment tool was designed using U.S. CDC metrics for clear communication. Assessment parameters included clarity of language, lexical diversity, conciseness and completeness, engagement with health information, and overall health literacy, reflecting patient communication proficiency and efficacy. The rubric was recursively optimized using novel synthetic transcript generation and prompt engineering approaches. Final validation was conducted over open-source, patient-doctor transcript databases from the U.S. Department of Veteran Affairs.
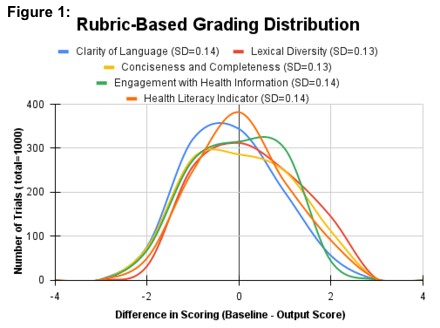
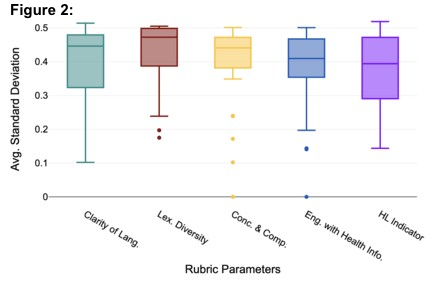
Results/Data: A consistent rubric-based input was developed with scores ranging from 1-4 in each of the five communication parameters (20 total points). Variability in score output was assessed by calculating the average standard deviation (SD) across 50 independent evaluations of n=20 fixed synthetic transcript (Figure 1), yielding distributions with an average standard deviation of 0.14 (SD=0.007). This confirms the ability of the model to consistently interpret, apply, and score the rubric-based input. Next, the model was assessed across each rubric parameter, plotting the average SD across 100 independent gradings of n=31 real patient-doctor transcripts (Figure 2). This resulted in an average SD of 0.39 (SD=0.02) for each category parameter and an overall score SD=1.23, presenting high category-wise grading consistency with real transcripts.
Conclusions: CHAT provides a rigorous, scalable, and objective mechanism for evaluating patient communication skills. Its standardized scoring allows educators, healthcare providers, and researchers to quantify improvements in health literacy interventions and assess clinical communication objectively, enhancing personalized healthcare education and practice into the future.
Tummala, Aditya
(
Harvard University
, Brookings , South Dakota , United States )
Ramesh, Pranav
(
Harvard University
, Brookings , South Dakota , United States )
Latif, Zara
(
Massachusetts General Hospital
, Cambridge , Massachusetts , United States )
Nelson, Beier
(
Harvard University
, Brookings , South Dakota , United States )
Quintana, Yuri
(
Beth Israel Deaconess Medical Center
, Boston , Massachusetts , United States )
Author Disclosures:
Aditya Tummala:DO NOT have relevant financial relationships
| Pranav Ramesh:DO NOT have relevant financial relationships
| Zara Latif:DO NOT have relevant financial relationships
| Beier Nelson:No Answer
| Yuri Quintana:No Answer