A Remedy for the Heart and the Hemoglobin: Improvement in Anemia Post Transcatheter Aortic Valve Replacement
Matta Raghav, Roy Aanya, Hammad Bayan, Draffen Arvind, Natsheh Zachary, Tiu Daniel, Tiu David, Salem Edward, Balami Jesse, Kalagara Swetha, Gupta Neil, Uraizee Omar, Sahgal Savina, Mishra Atreya, Ene Adriana, Hattab Aleyah, Arora Aarushi, Sufyaan Humam, Dau Trang, Silberstein Jonathan, Yu Julia, Torres Kayla, Seshadri Suhas, Navarro Laura, Singam Manisha, Ismail Mariam, Rana Riya, Habeel Samer, Liu Simon, Chaganti Srinidhi, Gurbuxani Vidur, Dwyer Kaluzna Stephanie, Groo Vicki, Carlson Andrew, Shroff Adhir, Bhayani Siddharth, Khan Azmer, Bhattaram Rohan, Zhang Runze, Shah Pal
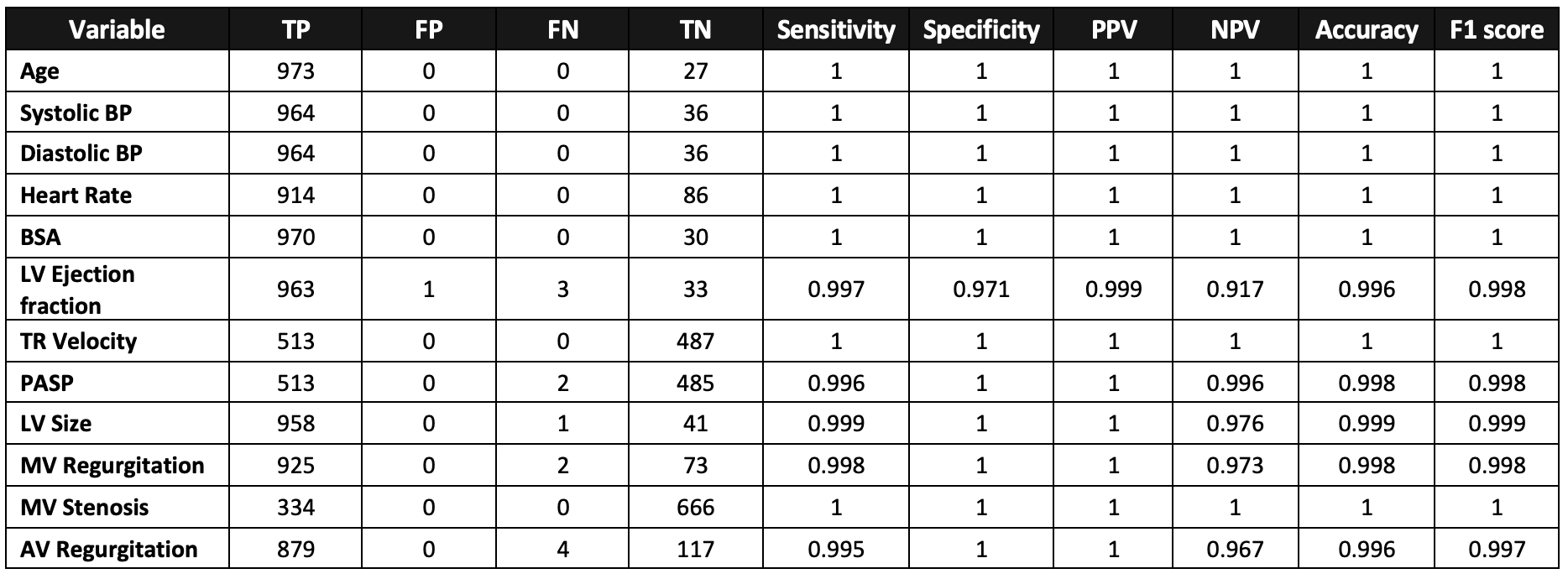
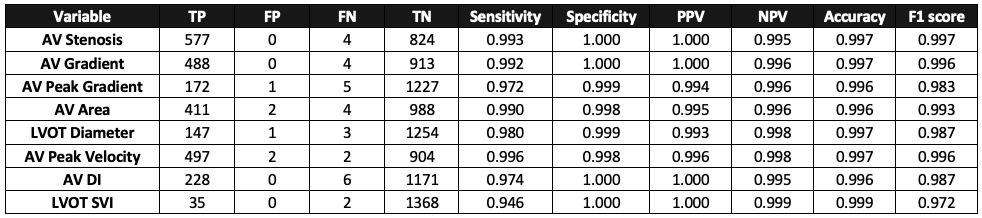
Utilization and Efficacy of an Automated Transthoracic Echocardiographic Report Data Extraction
Praveen Nischal, Shah Anish, Hill Michael, Tofovic David