Leveraging Large Language Models (LLMs) For Randomized Clinical Trial Summarization
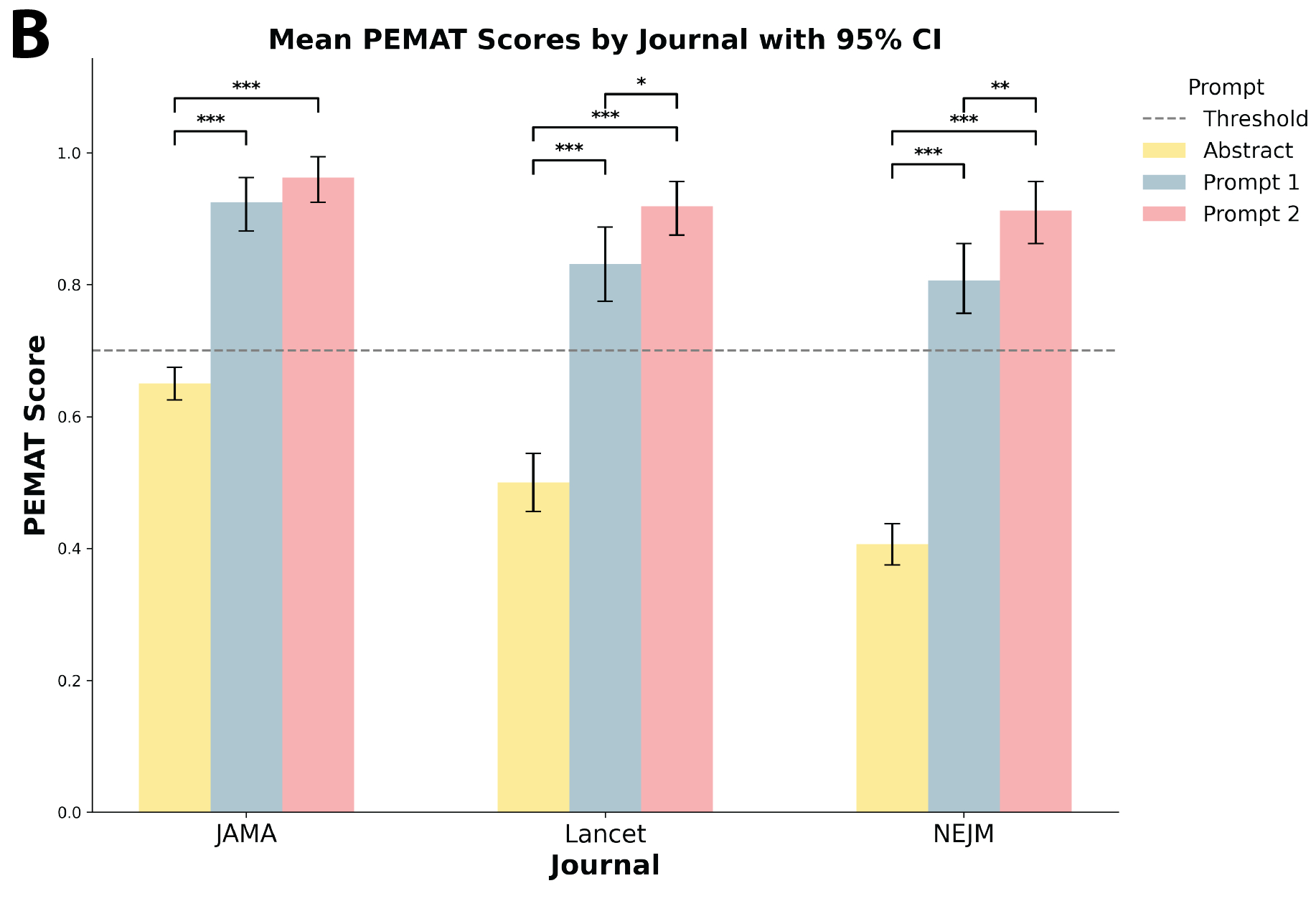
Abstract Body (Do not enter title and authors here): Background: With widespread scientific misinformation, access to primary literature, such as randomized clinical trials (RCTs), can empower patients in their decision-making about their health. However, scientific publications for RCTs – the bedrock of evidence-based cardiovascular care – are not written in accessible language for patients. We hypothesized that large language models (LLMs) could appropriately summarize RCTs into understandable language based on evaluation objective tools, enhancing patient-provider communication and informed consent. Methods: From the 3 major medical journals, we extracted 60 RCTs published between January and December 2023. Of these RCTs, 28% were cardiovascular. Each study’s abstract was the used as the reference text or the publicly available summary. Using the chat interface of GPT4, (1) we prompted it to summarize the complete articles to maximize patient understandability (Prompt 1), and (2) prompted it to score 100% on the Patient Education Materials Assessment Tool (PEMAT), a scoring system for evaluating health literacy developed by the AHRQ (Prompt 2). Two evaluators scored original article abstracts, Prompt 1 and Prompt 2. The 8 relevant PEMAT Understandability Scale Questions scored 0 (not present) or 1 (present), with a mean of 0.7 representing the accepted threshold for understandability [A]. Results: The abstracts scored a 0.5 (IQR 0.4, 0.6) on PEMAT, with 8.3% scoring above 0.7, with significant differences across the 3 journals [B]. Prompt 1 scored a 0.9 (IQR 0.8, 1.0), with 83.3% scoring above 0.7, and Prompt 2 scored a 1.0 (0.9, 1.0) and higher than Prompt 1 (p<.001), with 100% scoring above 0.7 [B]. Both Prompts scored higher than the respective abstracts (p<.001). These patterns were consistent across cardiovascular and non-cardiovascular RCTs. The domains where there were most substantial improvements from abstracts to Prompts 1 and 2 included the degree of distracting information, use of everyday language, explanation of medical terms, and of numbers, and without the need to do calculations. Conclusion: LLMs that are primed to align summaries with levels of health literacy, and especially with objective scores, can enable patients to have accessible and reliable information by summarizing primary clinical literature in language understandable to patients.
Mangla, Anjali
(
Yale University
, New Haven , Connecticut , United States )
Thangaraj, Phyllis
(
Yale University
, New Haven , Connecticut , United States )
Khera, Rohan
(
Yale School of Medicine
, New Haven , Connecticut , United States )
Author Disclosures:
Anjali Mangla:DO NOT have relevant financial relationships
| Phyllis Thangaraj:DO NOT have relevant financial relationships
| Rohan Khera:DO have relevant financial relationships
;
Research Funding (PI or named investigator):Bristol-Myers Squibb:Active (exists now)
; Ownership Interest:Ensight-AI, Inc:Active (exists now)
; Ownership Interest:Evidence2Health LLC:Active (exists now)
; Research Funding (PI or named investigator):BridgeBio:Active (exists now)
; Research Funding (PI or named investigator):Novo Nordisk:Active (exists now)