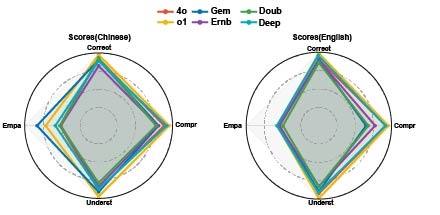
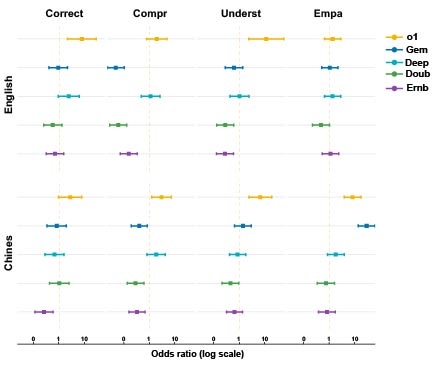
A ChatGLM-based stroke diagnosis and prediction tool
Song Xiaowei, Wang Jiayi, Ma Weizhi, Wu Jian, Wang Yueming, Gao Ceshu, Wei Chenming, Pi Jingtao
A Contemporary Machine Learning-Based Risk Stratification for Mortality and Hospitalization in Heart Failure with Preserved Ejection Fraction Using Multimodal Real-World Data
Fudim Marat, Weerts Jerremy, Patel Manesh, Balu Suresh, Hintze Bradley, Torres Francisco, Micsinai Balan Mariann, Rigolli Marzia, Kessler Paul, Touzot Maxime, Lund Lars, Van Empel Vanessa, Pradhan Aruna, Butler Javed, Zehnder Tobias, Sauty Benoit, Esposito Christian, Balazard Félix, Mayer Imke, Hallal Mohammad, Loiseau Nicolas