Performance of Multimodal LLMs in ECG Interpretation: A Comparative Analysis of ChatGPT and Google Gemini for ECG Diagnosis
Abstract Body (Do not enter title and authors here): Background: Multimodal Large Language Models (LLMs) such as ChatGPT (4o mini) and Gemini (2.5 Flash) have shown proficiency in textual tasks, yet their performance in ECG image interpretation is underexplored. ECG interpretation is vital but complex, with notable inter-reader variability. This study evaluates their diagnostic accuracy under two conditions—image-only (simulating patient self-assessment) and image plus brief history (simulating clinician perspective)—with outputs assessed independently and in a blinded fashion.
Research Question: Do LLM models like ChatGPT and Google Gemini exhibit consistent diagnostic accuracy in ECG interpretation, and how does their performance contrast with clinicians?
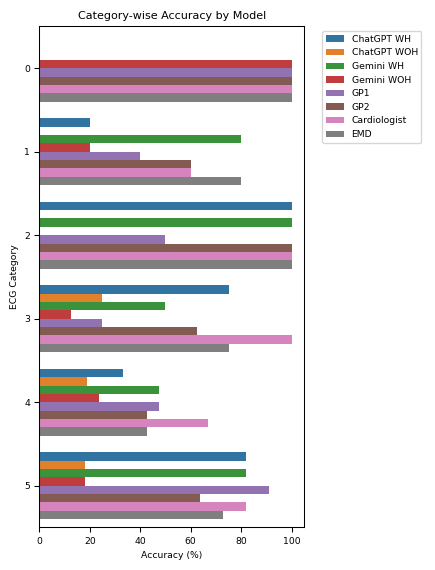
Methods: We used fifty 12-lead ECGs across six diagnostic categories: 0—Normal, 1—Coronary Heart Disease, 2—Hypertrophy Patterns, 3—AV Block and Bundle Branch Block, 4—Supraventricular and Ventricular Rhythms, and 5—Miscellaneous/Rare. Both models independently interpreted ECGs under the two conditions. Ground-truth diagnoses were based on expert consensus, with evaluators blinded to model outputs. Performance was benchmarked against four clinicians (2 General Practitioners, 1 cardiologist, and 1 emergency physician) and measured as overall and per-category accuracy, sensitivity, and specificity. Paired t-tests and Wilcoxon signed-rank tests (p<0.05) assessed differences. The study was conducted in accordance with STARD guidelines.
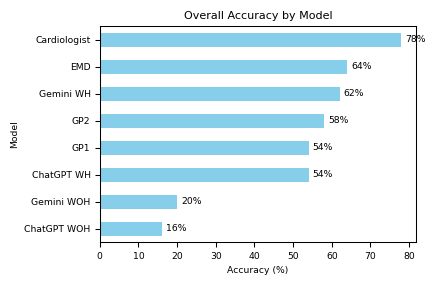
Results: With clinical history, Google Gemini achieved 62.0% accuracy and ChatGPT 54.0%; without history, accuracy dropped to 20.0% and 16.0%, respectively. Clinicians’ accuracies were cardiologist 78.0%, emergency physician 64.0%, GP2 58.0%, and GP1 54.0%. Subgroup analysis by diagnostic category revealed that incorporating clinical history significantly improved performance overall, with ChatGPT showing significant accuracy variability across categories (X2=15.37, p=0.0089) and similar trends observed for Gemini: t=4.88, p=0.000012; ChatGPT: t=4.73, p=0.000019.
Conclusion: Multimodal LLMs benefit from contextual clinical input when interpreting ECGs. Although Gemini outperformed ChatGPT, both lag behind clinicians—especially the cardiologist—with high specificity but low sensitivity without history. These findings highlight the limitations of general-purpose LLMs in ECG interpretation and the importance of domain-specific training. Hybrid models that integrate LLMs with clinician oversight may enhance future diagnostic workflows.
Guntupalli, Yashaswi
(
Sri Venkateswara Institute of Medical Sciences - SPMCW
, Tirupati , Andhra Pradesh , India )
Yannakula, Venkata
(
Kasturba Medical College Manipal
, Manipal , India )
Peri, Sri Sai Githa
(
SVIMS-SPMCW
, Tirupati , India )
Alluri, Amruth
(
American University of the Caribbean School of Medicine
, Cupecoy , Sint Maarten (Dutch part) )
Author Disclosures:
Yashaswi Guntupalli:DO NOT have relevant financial relationships
| Venkata Yannakula:DO NOT have relevant financial relationships
| Sri Sai Githa Peri:DO NOT have relevant financial relationships
| Amruth Alluri:No Answer