My AI Ate My Homework: Measuring ChatGPT Performance on the American College of Cardiology Self-Assessment Program
Abstract Body (Do not enter title and authors here): Background: Artificial intelligence (AI) is a rapidly growing field with promising utility in health care. ChatGPT is a language learning model by OpenAI trained on extensive data to comprehend and answer a variety of questions, commands, and prompts. Despite the promise AI offers, there are still glaring deficiencies.
Methods: 310 questions from the American College of Cardiology Self-Assessment Program (ACCSAP) question bank were queried. 50% of questions from each of the following sections were randomly selected: coronary artery disease, arrhythmias, valvular disease, vascular disease, systemic hypertension and hypotension, pericardial disease, systemic disorders affecting the circulatory system, congenital heart disease, heart failure and cardiomyopathy, and pulmonary circulation. Questions were fed into ChatGPT Legacy 3.5 version with and without answer choices and the accuracy of its responses were recorded. Statistical analysis was performed using Microsoft Excel statistical package.
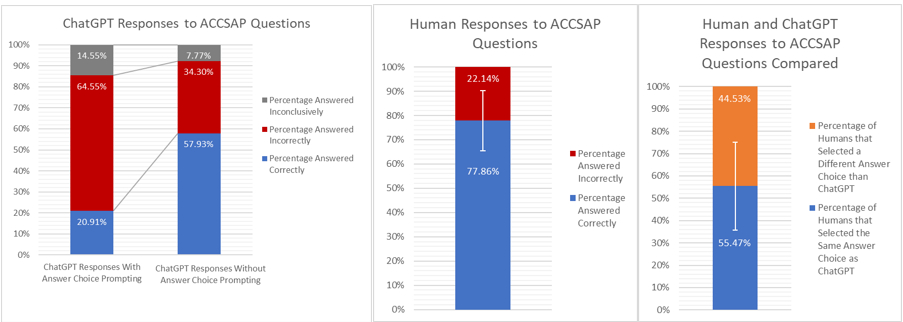
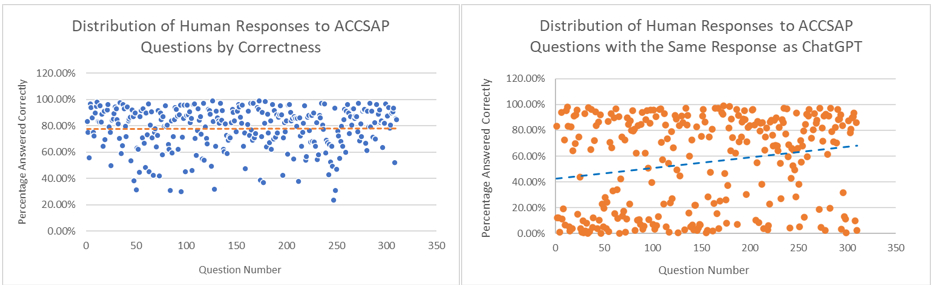
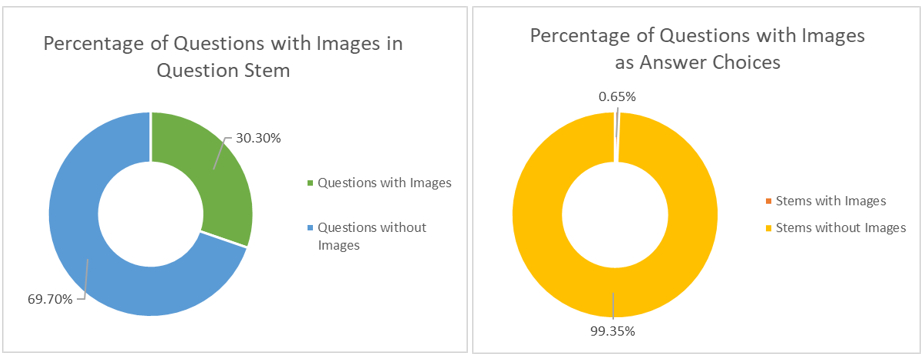
Results: Human respondents were 77.86% accurate +/- 16.01% with an IQR of 21.08% on average. Without answer choice prompting, ChatGPT was correct 57.93% and inconclusive 7.77% of the time. When prompted with answer choices, ChatGPT was correct only 20.91% and inconclusive 14.55% of the time. Additionally, an average of 55.47% +/- 35.55% of human respondents with an IQR of 73.19% selected the same answer choice as ChatGPT. Finally, on a scale of 1 to 5, with 1 being the most picked and 5 being the least picked, human respondents selected the same response as ChatGPT an average of 1.66 out of 5. 30.32% or 94 of the 310 questions contained images in the question stem. Only 0.65% or 2 out of the 310 questions contained images in the answer choices.
Conclusion: To our knowledge, the performance of ChatGPT in the field of cardiology board preparation is limited. Our analysis shows that while AI software has become increasingly more comprehensive, progress is still needed to accurately answer complex medical questions.
Hossain, Afif
(
Rutgers New Jersey Medical School
, Newark , New Jersey , United States )
Shaikh, Anam
(
Rutgers New Jersey Medical School
, Newark , New Jersey , United States )
Hossain, Sarah
(
American University of Antigua
, Coolidge , Antigua and Barbuda )
Shaikh, Amina
(
Rutgers University
, New Brunswick , New Jersey , United States )
Thomas, Renjit
(
East Orange Veteran's Administration
, East Orange , New Jersey , United States )
Author Disclosures:
Afif Hossain:DO NOT have relevant financial relationships
| Anam Shaikh:DO NOT have relevant financial relationships
| sarah hossain:No Answer
| Amina Shaikh:No Answer
| Renjit Thomas:No Answer