Automatic assignment of CAD-RADS categories in coronary CTA reports using large language model
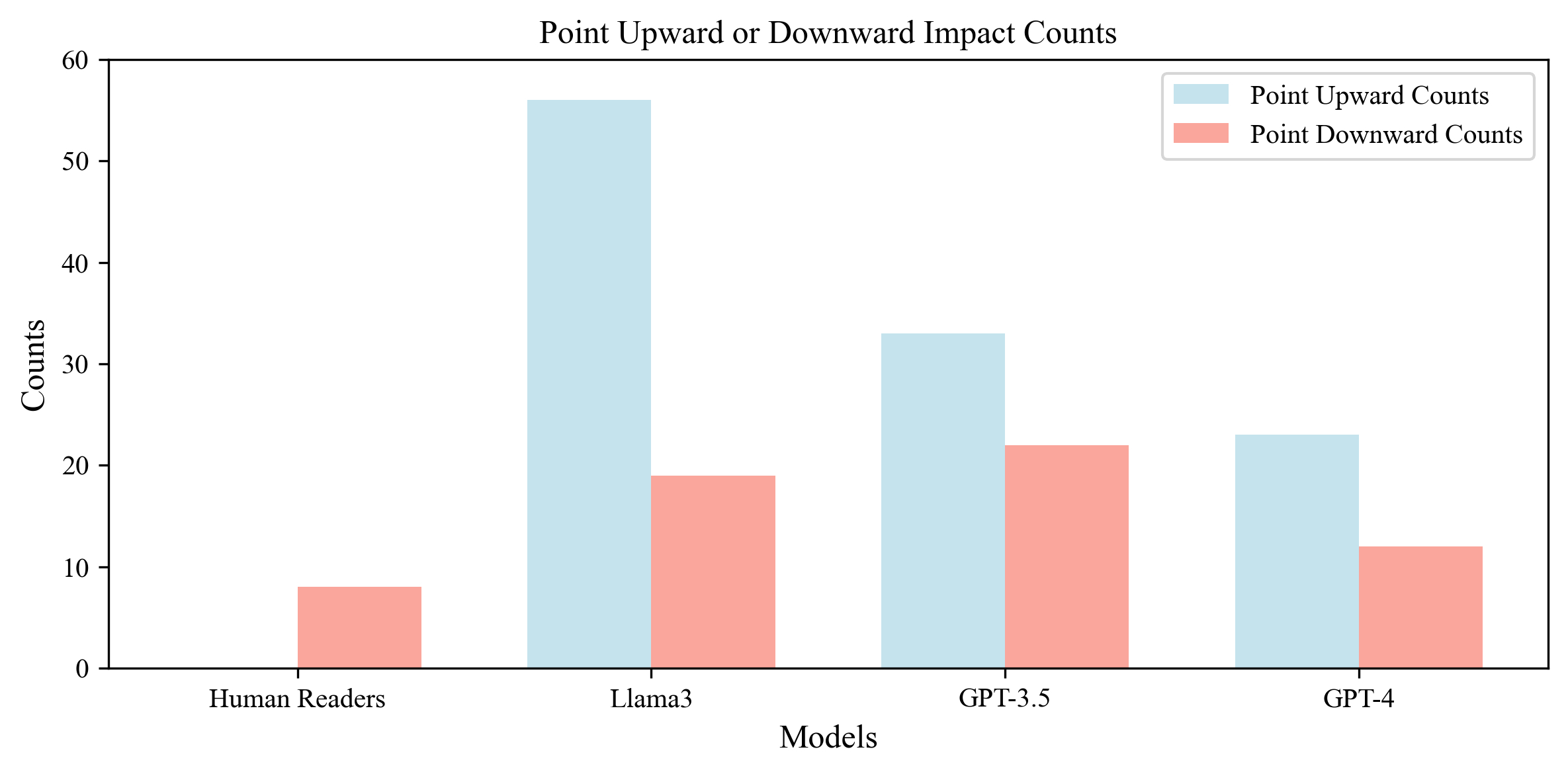
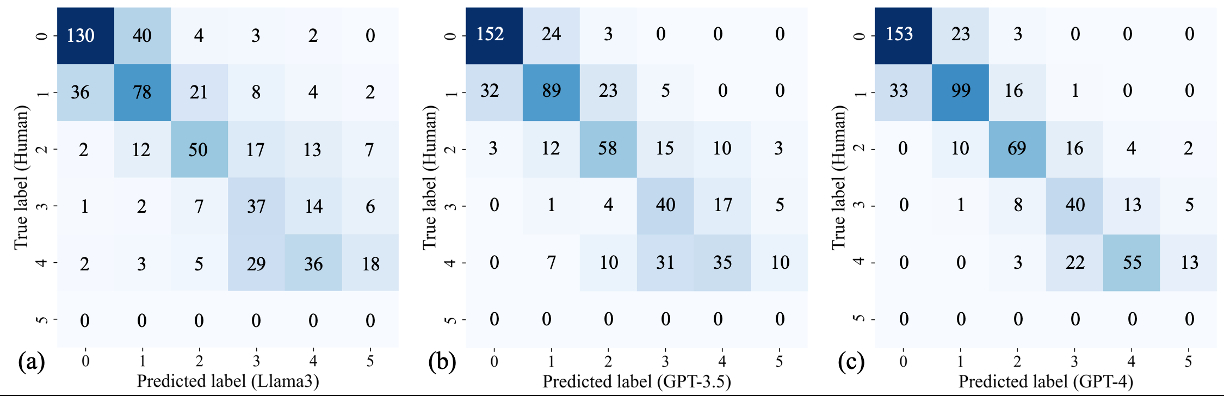
Abstract Body (Do not enter title and authors here): Background The effectiveness of different large language models (LLM) in extracting important information from CT angiography (CTA) radiology reports is unknown. Purpose The Coronary Artery Disease-Reporting and Data System (CAD-RADS) is a standardized reporting system for CTA that categorizes the severity of coronary artery disease to aid in clinical decision-making. To evaluate the agreement between human readers and LLMs in assigning CAD-RADS categories based on CTA reports. Materials and Methods This retrospective study analyzed reports from patients who underwent coronary CTA for screening or diagnosis at Johns Hopkins Hospital. Reports with CAD-RADS 0–5 findings were collected from Jan. 2020 to Oct. 2023. Initially, 6,212 CTA reports were retrieved. After excluding non-organized reports and retaining only those with CAD-RADS scores, 590 reports remained. Board-certified radiologists and three large language models (GPT-3.5, GPT-4, and Llama3) assigned CAD-RADS categories based on the original radiologists' findings. Two radiologists reviewed the CAD scores, with only one discrepancy in the 590 reports, indicating high inter-agreement. Agreement between human readers and LLMs for CAD-RADS categories was assessed using the Gwet agreement coefficient (AC1 value). Frequencies of changes in CAD-RADS category assignments that could potentially affect clinical management (CAD-RADS 0-2 vs. 3-5) were calculated and compared. Typically, CAD-RADS 0-2 indicates mild disease leading to conservative management, while CAD-RADS 3-5 denotes further testing or disease requiring aggressive intervention to prevent adverse cardiovascular events. Results Among 590 reports, agreement between original and reviewing radiologists was almost perfect (AC1 = 0.985). Good agreement was also found between original radiologists and Llama3, GPT-3.5, and GPT-4 (AC1 = 0.861, 0.907, 0.941, respectively). Differences in CAD-RADS category upgrades/downgrades potentially affecting clinical management were observed: 0 of 590 (0%) for human readers, 56 of 590 (9.4%) for Llama3, 33 of 590 (5.5%) for GPT-3.5, and 23 of 590 (3.9%) for GPT-4 upgrading CAD-RADs; 8 of 590 (1.4%) for human readers, 19 of 590 (3.2%) for Llama3, 22 of 590 (3.7%) for GPT-3.5, and 12 of 590 (2.0%) for GPT-4 downgrading RAD-CADs. Conclusion LLMs showed good agreement with human readers in assigning CAD-RADS categories on CTA reports. However, they were more likely to upgrade CAD-RADS category when compared to radiologists.
Wang, Yuli
(
Johns Hopkins University
, Baltimore , Maryland , United States )
Hsu, Wen-chi
(
Johns Hopkins University
, Baltimore , Maryland , United States )
Dai, Yuwei
(
Central South University
, Changsha , China )
Shi, Victoria
(
Johns Hopkins University
, Baltimore , Maryland , United States )
Bai, Harrison
(
Johns Hopkins University
, Baltimore , Maryland , United States )
Lin, Cheng Ting
(
Johns Hopkins University
, Baltimore , Maryland , United States )
Author Disclosures:
Yuli Wang:DO NOT have relevant financial relationships
| Wen-Chi Hsu:No Answer
| Yuwei Dai:No Answer
| Victoria Shi:No Answer
| Gigin Lin:DO NOT have relevant financial relationships
| Harrison Bai:No Answer
| Cheng Ting Lin:DO have relevant financial relationships
;
Research Funding (PI or named investigator):Siemens Healthcare:Active (exists now)